Low-Light Image Enhancement with Normalizing Flow
1. Rapid-Rich Object Search Lab (ROSE), Nanyang Technological University 2. City University of Hong Kong
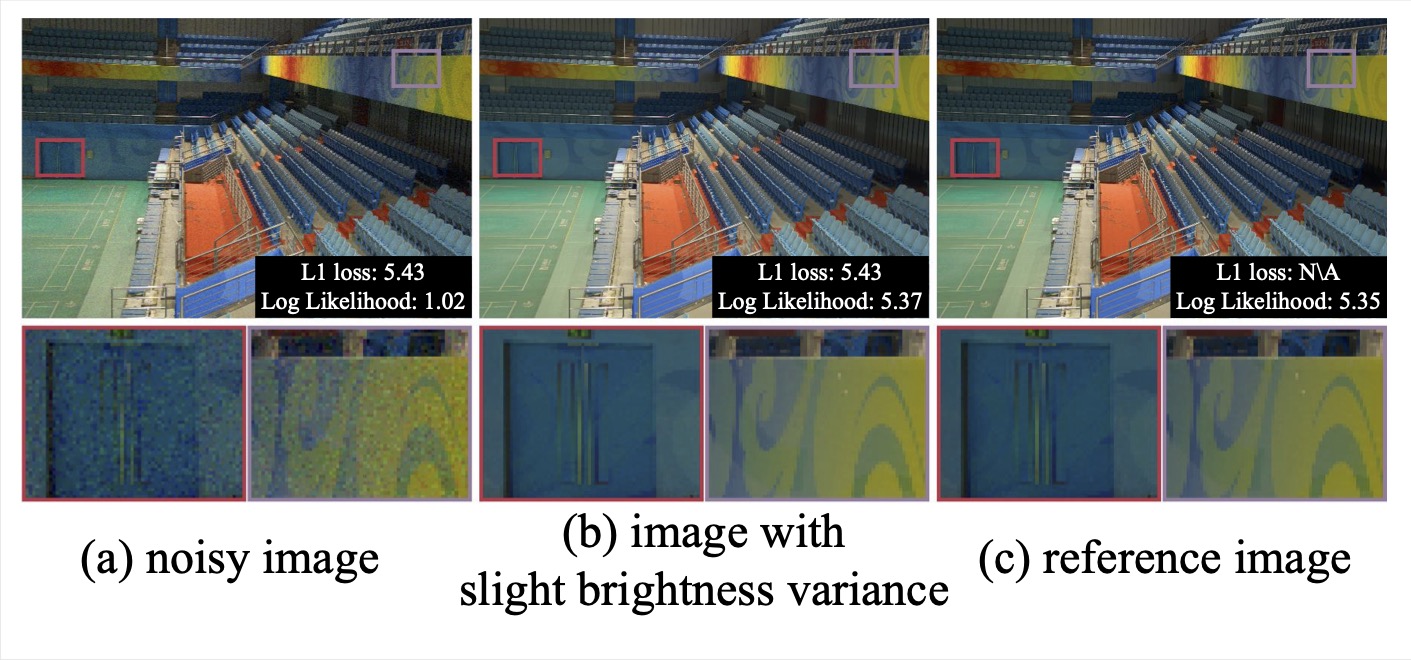
Illustration of the superiority of our normalizing flow model in measuring the visual distance compared to L1 reconstruction loss for low-light image enhancement. Although (b) is more visually similar to (c), i.e., reference image, than (a), their L1 reconstruction losses are the same. Benefiting from better capturing the complex conditional distribution of normally exposed images, our model can better capture the error distribution and therefore provide the measure results more consistent with human vision.
Abstract
To enhance low-light images to normally-exposed ones is highly ill-posed, namely that the mapping relationship between them is one-to-many. Previous works based on the pixel-wise reconstruction losses and deterministic processes fail to capture the complex conditional distribution of normally exposed images, which results in improper brightness, residual noise, and artifacts. In this paper, we investigate to model this one-to-many relationship via a proposed normalizing flow model. An invertible network that takes the low-light images/features as the condition and learns to map the distribution of normally exposed images into a Gaussian distribution. In this way, the conditional distribution of the normally exposed images can be well modeled, and the enhancement process, i.e., the other inference direction of the invertible network, is equivalent to being constrained by a loss function that better describes the manifold structure of natural images during the training. The experimental results on the existing benchmark datasets show our method achieves better quantitative and qualitative results, obtaining better-exposed illumination, less noise and artifact, and richer colors.
Method Highlight
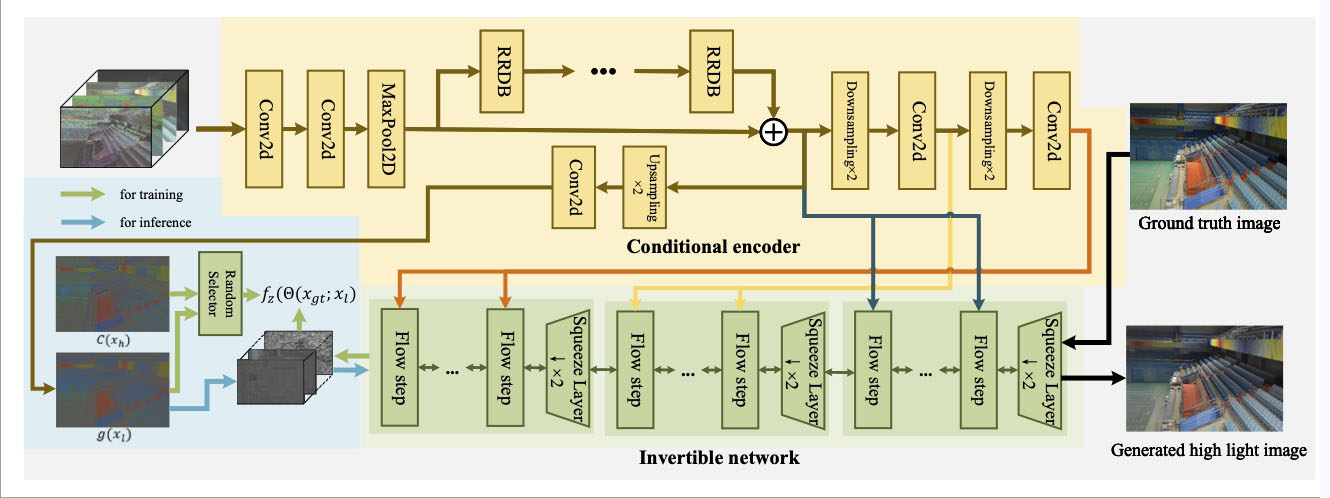
The architecture of our proposed LLFlow. Our model consists of a conditional encoder to extract the illumination-invariant color map and an invertible network that learns a distribution of normally exposed images conditioned on a low-light one. For training, we maximize the exact likelihood of a high-light image by using change of variable theorem and a random selector is used to obtain the mean value of latent variable
which obey Gaussian distribution from the color map
of reference image or the extracted color map
from low-light image through the conditional encoder. For inference, we can randomly select
from
to generate different normally exposed images images with different brightness levels
from the learned conditional distribution
.
(The color maps in the blue area are squeezed to the same size with latent feature
.)
Experiment Results
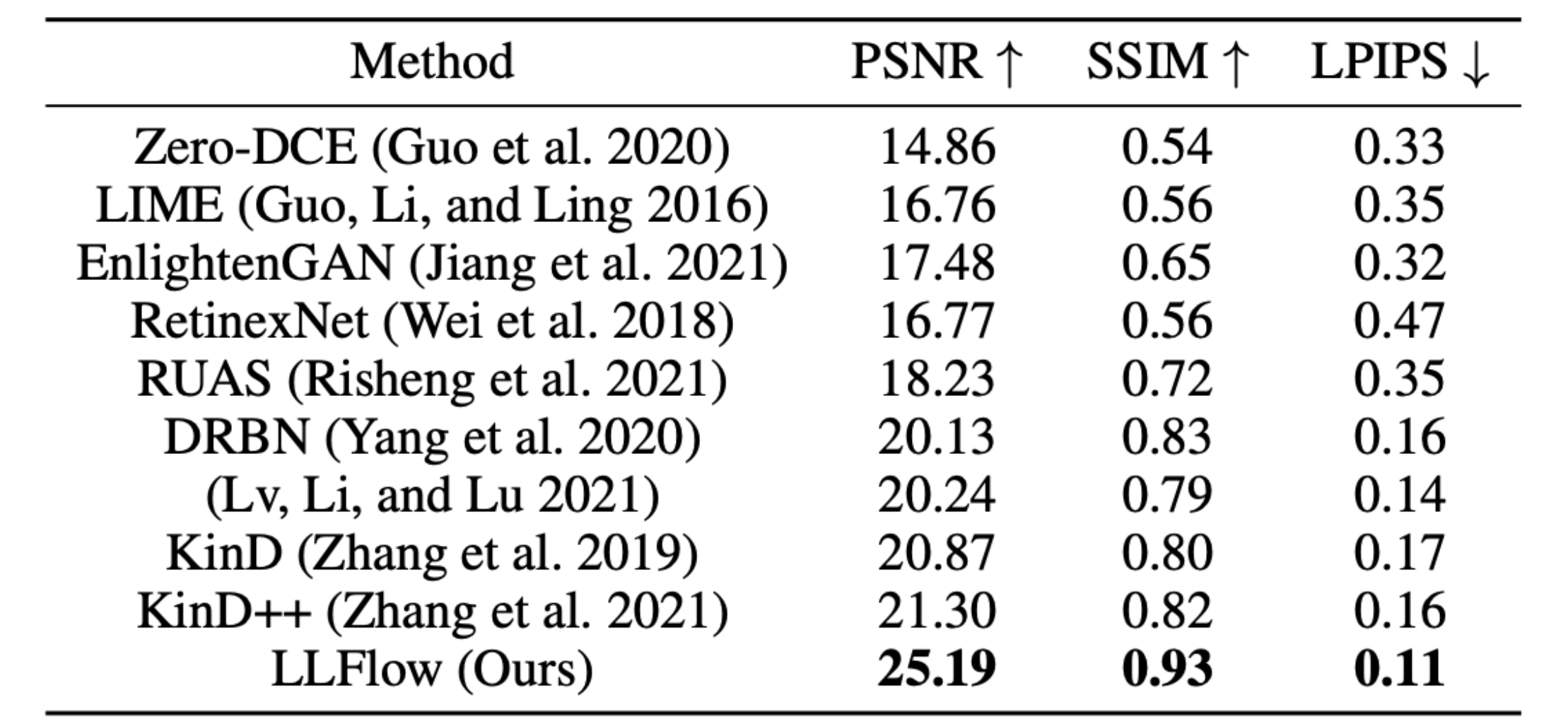 Quantitative comparison on the LOL dataset in terms of PSNR, SSIM and LPIPS. ↑ (↓) denotes that, larger (smaller) values lead to better quality. |
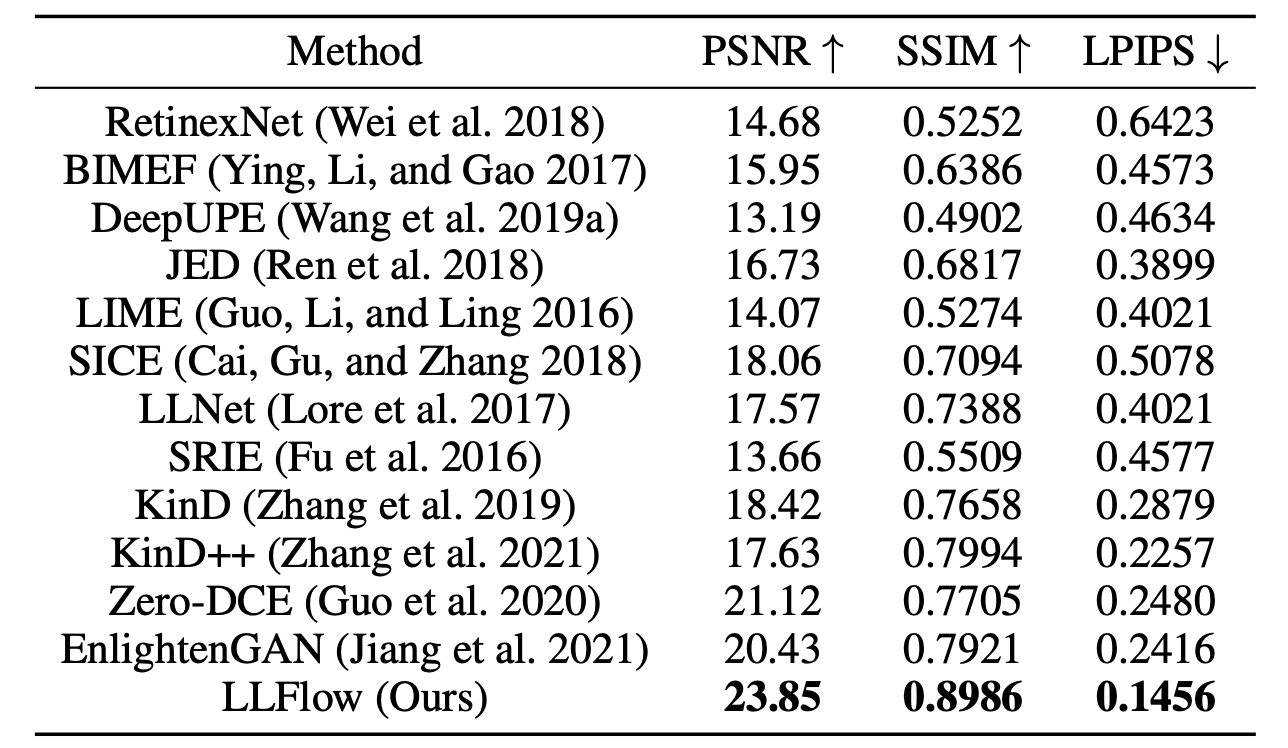 Quantitative comparison on the VE-LOL dataset in terms. The models are trained on the LOL or their own dataset. ↑ (↓) denotes that, larger (smaller) values lead to better quality |

Visual comparison with state-of-the-art low-light image enhancement methods on LOL dataset. The normally exposed image generated by our method has less noise and artifact, and better colorfulness.
Materials
 Paper |
 Supplementary |
Code |
Citation
@article{wang2021low,
title={Low-Light Image Enhancement with Normalizing Flow},
author={Wang, Yufei and Wan, Renjie and Yang, Wenhan and Li, Haoliang and Chau, Lap-Pui and Kot, Alex C},
journal={arXiv preprint arXiv:2109.05923},
year={2021}
}
}